Natural Language Processing (NLP), as a subcategory of Artificial Intelligence, has continued to grow in its practice by the real estate industry. This growth is evident as seen by the proliferation of chatbots on real estate websites and new innovative products like Homebot – who won the 2018 Realogy FWD Innovation Award. Let’s dip into Natural Language Processing and how to use it for SEO in real estate blog articles.
 Computers love structured data that neatly fits into rows and columns like in an Excel spreadsheet. They can do all kinds of things when dealing solely with 1’s and 0’s.
Computers love structured data that neatly fits into rows and columns like in an Excel spreadsheet. They can do all kinds of things when dealing solely with 1’s and 0’s.
When it comes to human language, computers have a difficult time processing information because we write and speak in an unstructured way. NLP’s job is to take unstructured natural language and structure it in a way a computer can read, understand, learn, and make sense of it in a valuable manner.
NLP accomplishes the above through a pipeline of tasks. An NLP pipeline of tasks are steps, which are required, to achieve desired results. It’s like when you wash a car. Before you begin washing the car with a sponge, there are several tasks to complete. Such as, getting the water hose out and connecting it to the spigot, finding a bucket to hold the soap and water and so on…
Determining Focus Keyword Phrases with NLP
Blogging is a vital marketing task for brokerages. Curating and publishing content around local real estate, lifestyle, and events, distinguishes a brokerage’s knowledge of the market. WAV Group does an excellent job of this marketing task and creates a fantastic data set for an NLP analysis of the best focus keyword phrases.
(Source: WAV Group – “OpenAI Says New AI too Risky for Full Disclosure.”
You can view the code on Kaggle.com – NLP for Real Estate.
Stemming
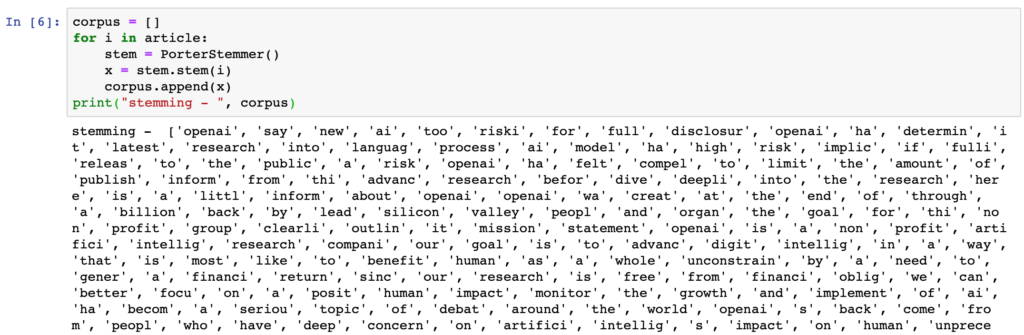
A step in the NLP pipeline normalizing words is to remove any suffix to expose its root form or stem. As an example, the Portman algorithm normalizes the words package, packages, and packaged to packag.

Google has been using stemming in search since 2003. The opportunity to use stemming for real estate is in property and lifestyle search features. Imagine a search experience where consumers are not limited to a street address, city, neighborhood, state, or zip code.
When we run the stemming process on the first few sentences from the article, this is the result.
Lemmatization
Stemming is desirable for developing quick search terms from an article, but some words lose their context. Look at the word “busi” in the above example. Computers are not able to understand this root as meaning business, busing, busier, or businessperson.
Lemmatizing in NLP finds the root, or lemma, of a word with its unconjugated verb form. Two words can be different but have the same meaning. As an example, let’s look at the next two sentences.
I had a penny.
I had two pennies.
When lemmatizing “I had two pennies”, turns into “I [have] two [penny].” If we used stemming on the words “penny and pennies”, the result is “penni”. Penni doesn’t have any contextual relevance to “penny or pennies”.

Let’s see what happens when we Lemmatize just the words in the article dataset.
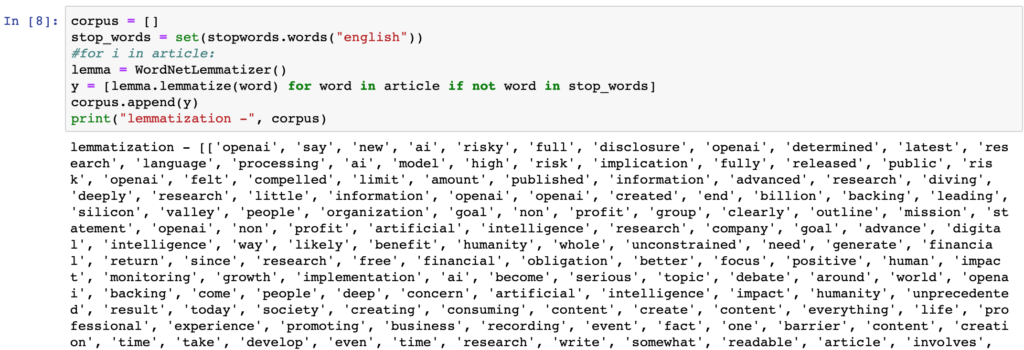
Notice the output doesn’t contain stop words like “to” and “the”. Applying an NLP pipeline task to remove stop words is a common classification technique.
Data Exploration
While this is terrific information to make keyword decisions, the next part is fascinating. There is a Python library to visualize the data in a word cloud. The larger the word in the visual, the more times the word is found in the text.
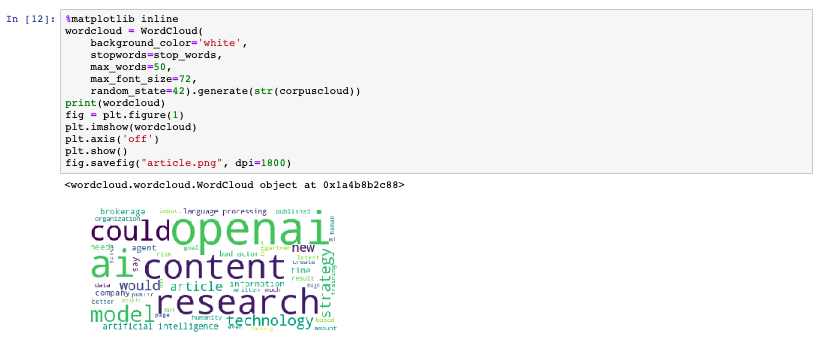
OpenAI and Research are the two most popular words and a possible contender for the article’s keyword phrase. Let’s dive deeper and see what else we can learn.
Keyword Phrase Evaluator
Why do you want to evaluate words to generate a keyword phrase? Didn’t Google do away with the keyword meta tag?
We don’t write blog articles with just SEO in mind. If we did, articles wouldn’t be readable for humans. Words used more often in an article help decide on titles and in knowing what appeals to search engines.
Yes, Google did remove the need to add keyword phrases into the keyword meta tag, but there are other SEO rules in which keyword phrases are essential.
Here are a few basic SEO rules that every blog post should obey for keyword phrases.
Articles need to contain keyword phrases in:
- Web address or URL.
- The main title
- Title tag.
- Description meta tag.
- The first paragraph.
Let’s review some of the keyword phrases and their score from the OpenAI article.
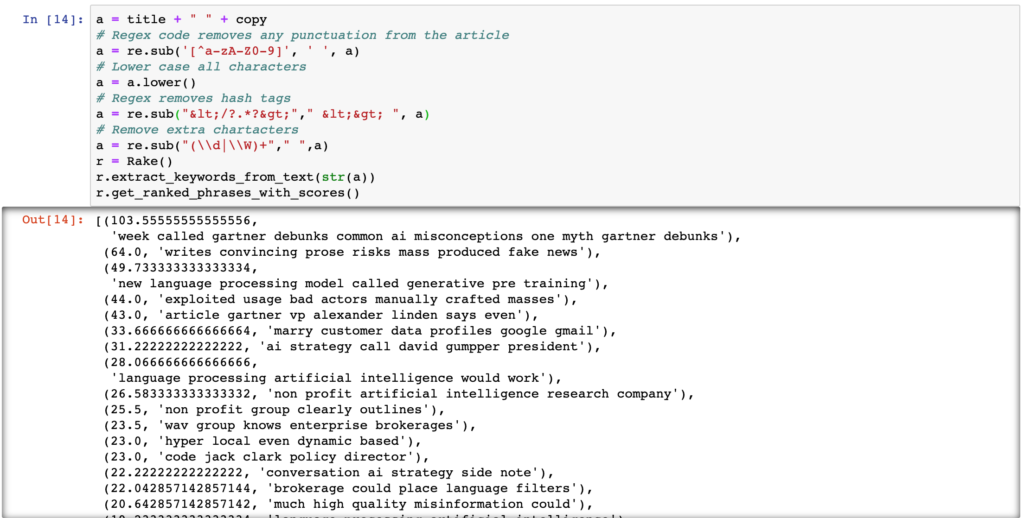
The results provide potential titles and keyword phrases to use for the article. The score is part of an algorithm from a paper written almost nine years ago. The source is mentioned at the end of the material.
Summary
NLP becomes very useful during SEO and Readability analysis of the many pages found on a real estate website. It is far easier to programmatically pull unstructured human language into structured data for analysis. Imagine manually reviewing every page on a site.
I do have one recommendation. Whoever has a blog on WordPress needs the Yoast SEO Pro plugin. Yoast SEO performs some of the above NLP pipeline tasks to recognize different word forms for SEO and readability.
The readability feature in the plugin is one of the best. Another essential feature is the Focus Keyword. This feature will keep you honest to the few basic SEO rules mentioned earlier.
Natural Language Processing has many opportunities within the real estate community. NLP can assist in compliance with the GDPR and California Consumer Privacy Act. Brokerages have millions of documents stored in digital archives. NLP is perfect for finding documents with Personal Identifiable Information (PII), storing the location of the documents, and if necessary, redacting certain PII information from different documents.
WAV Group is fully committed to NLP for statistical analysis and machine learning. If you have a project or need for regulatory compliance, WAV Group can provide a solution. We would love to write a case study on how a brokerage leveraged the benefits of NLP to enhance their business. Call Victor, Marilyn, or David for more information.
Sources:
Feature Image by Gordon Johnson from Pixabay
The Python library – Rake-NLTK – used for the Keyword Extraction is from an algorithm located in the paper “Automatic keyword extraction from individual documents by Stuart Rose, Dave Engel, Nick Cramer, and Wendy Cowley.”





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This is interesting.